Regression with Categorical Predictors
Regression with Categorical Predictors
This set of notes will explore using linear regression for a single predictor attribute that is categorical instead of continuous. To explore this first, let’s explore some data.
# install.packages("Lahman")
library(tidyverse)## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.4 ✔ readr 2.1.5
## ✔ forcats 1.0.0 ✔ stringr 1.5.1
## ✔ ggplot2 3.4.4 ✔ tibble 3.2.1
## ✔ lubridate 1.9.3 ✔ tidyr 1.3.1
## ✔ purrr 1.0.2
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorslibrary(Lahman)
library(ggformula)## Loading required package: scales
##
## Attaching package: 'scales'
##
## The following object is masked from 'package:purrr':
##
## discard
##
## The following object is masked from 'package:readr':
##
## col_factor
##
## Loading required package: ggridges
##
## New to ggformula? Try the tutorials:
## learnr::run_tutorial("introduction", package = "ggformula")
## learnr::run_tutorial("refining", package = "ggformula")theme_set(theme_bw(base_size = 18))
career <- Batting |>
filter(AB > 100) |>
anti_join(Pitching, by = "playerID") |>
filter(yearID > 1990) |>
group_by(playerID, lgID) |>
summarise(H = sum(H), AB = sum(AB)) |>
mutate(average = H / AB)## `summarise()` has grouped output by 'playerID'. You can override using the
## `.groups` argument.career <- People |>
tbl_df() |>
dplyr::select(playerID, nameFirst, nameLast) |>
unite(name, nameFirst, nameLast, sep = " ") |>
inner_join(career, by = "playerID") |>
dplyr::select(-playerID)## Warning: `tbl_df()` was deprecated in dplyr 1.0.0.
## ℹ Please use `tibble::as_tibble()` instead.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.head(career)## # A tibble: 6 × 5
## name lgID H AB average
## <chr> <fct> <int> <int> <dbl>
## 1 Jeff Abbott AL 127 459 0.277
## 2 Kurt Abbott AL 33 123 0.268
## 3 Kurt Abbott NL 455 1780 0.256
## 4 Reggie Abercrombie NL 54 255 0.212
## 5 Brent Abernathy AL 194 767 0.253
## 6 Shawn Abner AL 81 309 0.262Question
Suppose we are interested in the batting average of baseball players since 1990, that is, the average is:
\[ average = \frac{number\ of\ hits}{number\ of\ atbats} \]
Let’s first visualize this.
gf_density(~ average, data = career) |>
gf_labs(x = "Batting Average")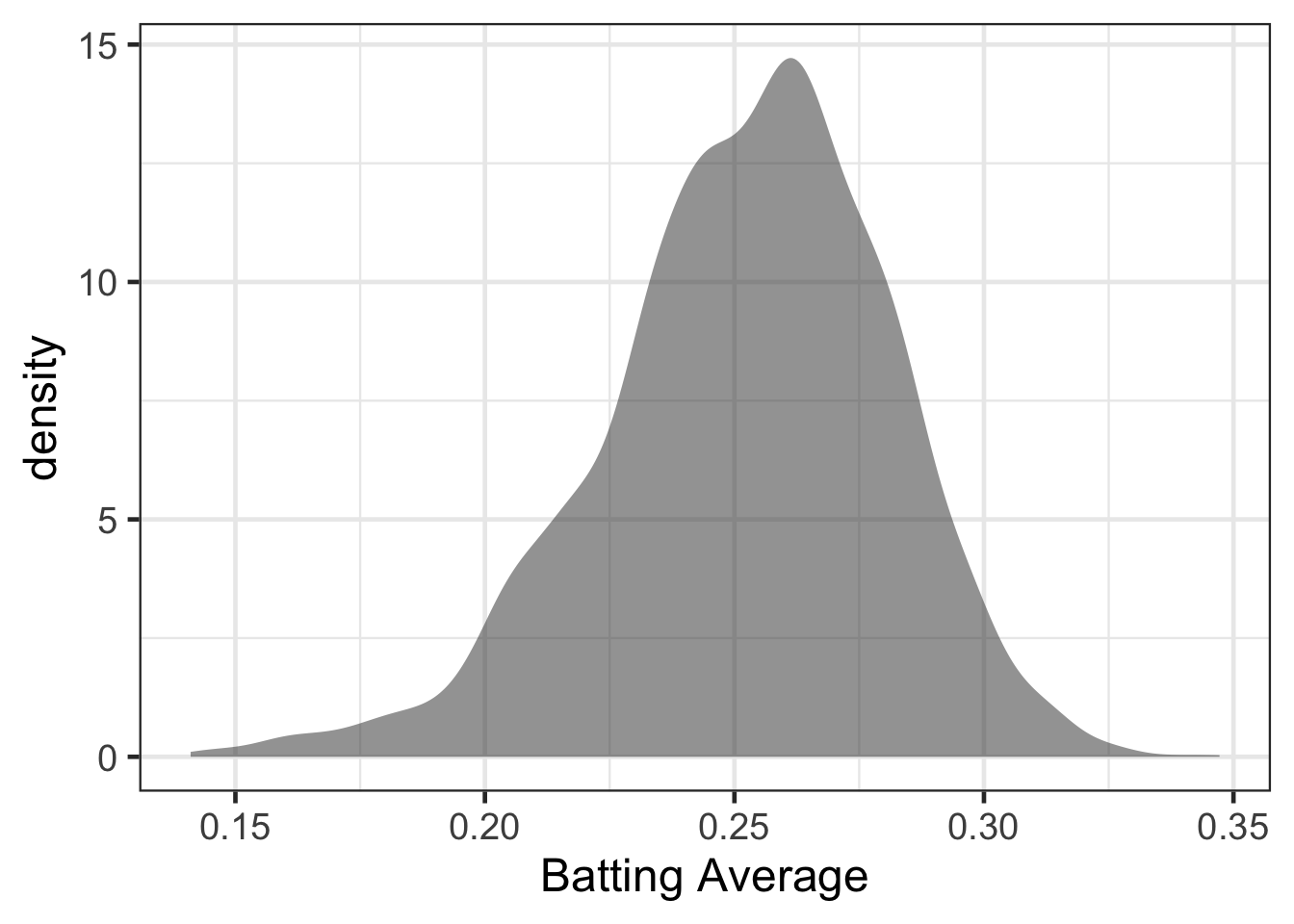
What if we hypothesized that the batting average will differ based on the league that players played in.
gf_violin(lgID ~ average, data = career, fill = 'gray80', draw_quantiles = c('0.1', '0.5', '0.9')) |>
gf_labs(x = "Batting Average",
y = "League")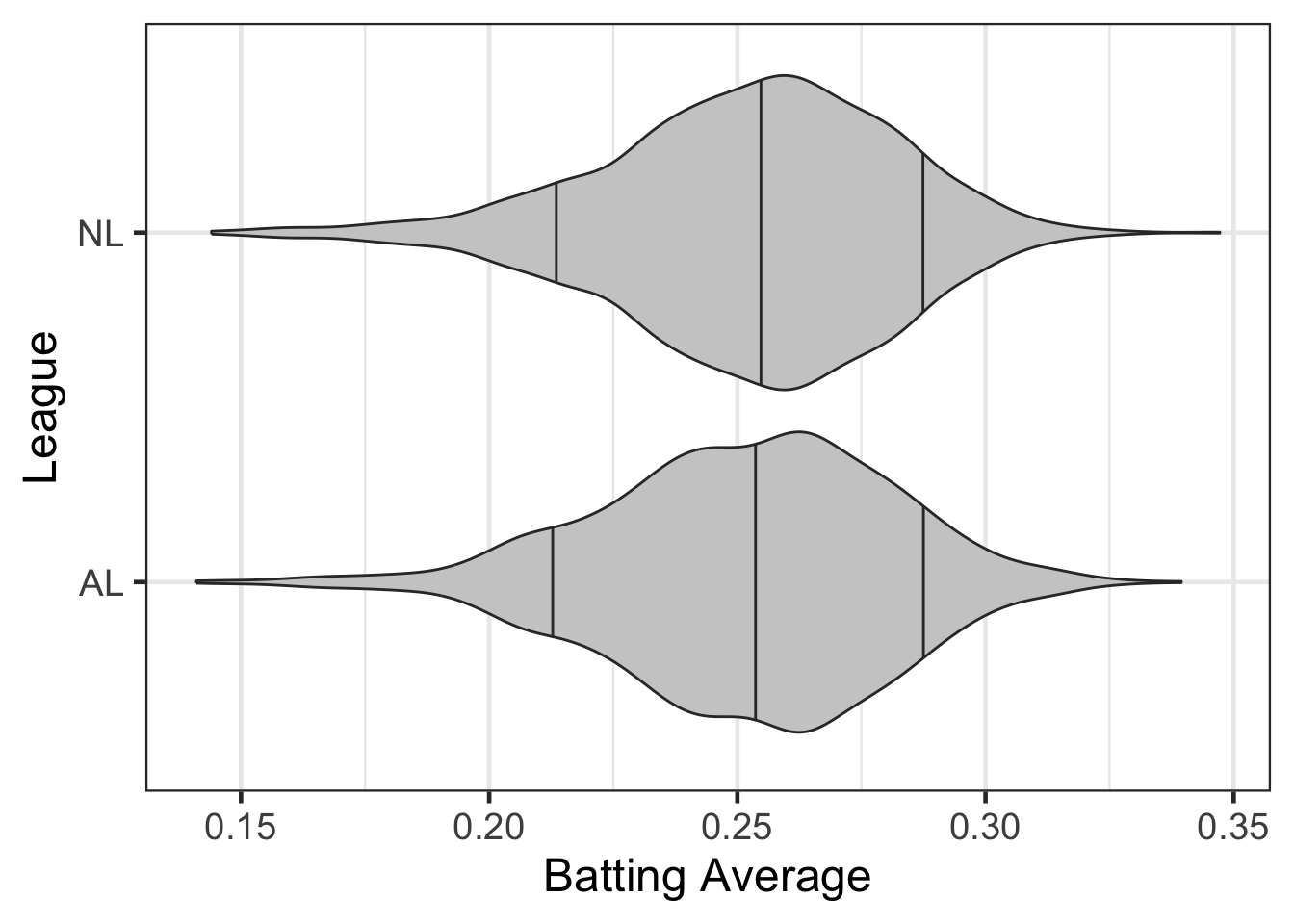
The distributions seem similar, but what if we wanted to go a step further and estimate a model to explore if there are really differences or not. For example, suppose we were interested in:
\[ H_{0}: \mu_{NL} = \mu_{AL} \]
What type of model could we use? What about linear regression?
Linear Regression with Categorical Attributes
Since these notes are happening, you can assume it is possible. But how can a categorical attribute with categories rather than numbers be included in the linear regression model?
The answer is that they can’t. We need a new representation of the categorical attribute, enter dummy or indicator coding.
Dummy/Indicator Coding
Suppose we use the following logic:
If NL, then give a value of 1, else give a value of 0.
Does this give the same information as before?
| League ID | Dummy League ID |
|---|---|
| AL | 0 |
| NL | 1 |
What would this look like for the actual data?
career <- career |>
mutate(league_dummy = ifelse(lgID == 'NL', 1, 0))
head(career, n = 10)## # A tibble: 10 × 6
## name lgID H AB average league_dummy
## <chr> <fct> <int> <int> <dbl> <dbl>
## 1 Jeff Abbott AL 127 459 0.277 0
## 2 Kurt Abbott AL 33 123 0.268 0
## 3 Kurt Abbott NL 455 1780 0.256 1
## 4 Reggie Abercrombie NL 54 255 0.212 1
## 5 Brent Abernathy AL 194 767 0.253 0
## 6 Shawn Abner AL 81 309 0.262 0
## 7 Shawn Abner NL 19 115 0.165 1
## 8 CJ Abrams NL 70 284 0.246 1
## 9 Bobby Abreu AL 858 3061 0.280 0
## 10 Bobby Abreu NL 1602 5373 0.298 1Now that there is a numeric attribute, these can be added into the linear regression model.
average_lm <- lm(average ~ league_dummy, data = career)
broom::tidy(average_lm)## # A tibble: 2 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.252 0.000758 333. 0
## 2 league_dummy 0.000558 0.00107 0.522 0.602How are these terms interpreted now?
df_stats(average ~ league_dummy, data = career, mean, sd, length)## response league_dummy mean sd length
## 1 average 0 0.2518959 0.02895094 1461
## 2 average 1 0.2524535 0.02896021 1477average_lm2 <- lm(average ~ lgID, data = career)
broom::tidy(average_lm2)## # A tibble: 2 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.252 0.000758 333. 0
## 2 lgIDNL 0.000558 0.00107 0.522 0.602t.test(average ~ lgID, data = career, var.equal = TRUE)##
## Two Sample t-test
##
## data: average by lgID
## t = -0.52189, df = 2936, p-value = 0.6018
## alternative hypothesis: true difference in means between group AL and group NL is not equal to 0
## 95 percent confidence interval:
## -0.002652537 0.001537330
## sample estimates:
## mean in group AL mean in group NL
## 0.2518959 0.2524535Values other than 0/1
First, I want to build off of the first part of the notes on regression with categorical predictors. Before generalizing to more than two groups, let’s first explore what happens when values other than 0/1 are used for the categorical attribute. The following three dummy/indicator attributes will be used:
- 1 = NL, 0 = AL
- 1 = NL, 2 = AL
- 100 = NL, 0 = AL
Make some predictions about what you think will happen in the three separate regressions?
library(tidyverse)
library(Lahman)
library(ggformula)
theme_set(theme_bw(base_size = 18))
career <- Batting |>
filter(AB > 100) |>
anti_join(Pitching, by = "playerID") |>
filter(yearID > 1990) |>
group_by(playerID, lgID) |>
summarise(H = sum(H), AB = sum(AB)) |>
mutate(average = H / AB)## `summarise()` has grouped output by 'playerID'. You can override using the
## `.groups` argument.career <- People |>
tbl_df() |>
dplyr::select(playerID, nameFirst, nameLast) |>
unite(name, nameFirst, nameLast, sep = " ") |>
inner_join(career, by = "playerID") |>
dplyr::select(-playerID)## Warning: `tbl_df()` was deprecated in dplyr 1.0.0.
## ℹ Please use `tibble::as_tibble()` instead.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.career <- career |>
mutate(league_dummy = ifelse(lgID == 'NL', 1, 0),
league_dummy_12 = ifelse(lgID == 'NL', 1, 2),
league_dummy_100 = ifelse(lgID == 'NL', 100, 0))
head(career, n = 10)## # A tibble: 10 × 8
## name lgID H AB average league_dummy league_dummy_12 league_dummy_100
## <chr> <fct> <int> <int> <dbl> <dbl> <dbl> <dbl>
## 1 Jeff… AL 127 459 0.277 0 2 0
## 2 Kurt… AL 33 123 0.268 0 2 0
## 3 Kurt… NL 455 1780 0.256 1 1 100
## 4 Regg… NL 54 255 0.212 1 1 100
## 5 Bren… AL 194 767 0.253 0 2 0
## 6 Shaw… AL 81 309 0.262 0 2 0
## 7 Shaw… NL 19 115 0.165 1 1 100
## 8 CJ A… NL 70 284 0.246 1 1 100
## 9 Bobb… AL 858 3061 0.280 0 2 0
## 10 Bobb… NL 1602 5373 0.298 1 1 100average_lm <- lm(average ~ league_dummy, data = career)
broom::tidy(average_lm)## # A tibble: 2 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.252 0.000758 333. 0
## 2 league_dummy 0.000558 0.00107 0.522 0.602average_lm_12 <- lm(average ~ league_dummy_12, data = career)
broom::tidy(average_lm_12)## # A tibble: 2 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.253 0.00169 150. 0
## 2 league_dummy_12 -0.000558 0.00107 -0.522 0.602average_lm_100 <- lm(average ~ league_dummy_100, data = career)
broom::tidy(average_lm_100)## # A tibble: 2 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.252 0.000758 333. 0
## 2 league_dummy_100 0.00000558 0.0000107 0.522 0.602Before moving to more than 2 groups, any thoughts on how we could run a one-sample t-test using a linear regression? For example, suppose this null hypothesis wanted to be explored.
\[ H_{0}: \mu_{BA} = .2 \]
\[ H_{A}: \mu_{BA} \neq .2 \]
Generalize to more than 2 groups
The ability to use regression with categorical attributes of more than 2 groups is possible and an extension of the 2 groups model shown above. First, let’s think about how we could represent three categories as numeric attributes. Suppose we had the following 4 categories of baseball players.
| Position |
|---|
| Outfield |
| Infield |
| Catcher |
| Designated Hitter |
# remotes::install_github("bdilday/GeomMLBStadiums")
library(GeomMLBStadiums)
ggplot() +
geom_mlb_stadium(stadium_ids = "twins",
stadium_segments = "all") +
facet_wrap(~team) +
coord_fixed() +
theme_void()
library(tidyverse)
library(Lahman)
library(ggformula)
theme_set(theme_bw(base_size = 18))
career <- Batting |>
filter(AB > 100) |>
anti_join(Pitching, by = "playerID") |>
filter(yearID > 1990) |>
group_by(playerID, lgID) |>
summarise(H = sum(H), AB = sum(AB)) |>
mutate(average = H / AB)## `summarise()` has grouped output by 'playerID'. You can override using the
## `.groups` argument.career <- Appearances |>
filter(yearID > 1990) |>
select(-GS, -G_ph, -G_pr, -G_batting, -G_defense, -G_p, -G_lf, -G_cf, -G_rf) |>
rowwise() |>
mutate(g_inf = sum(c_across(G_1b:G_ss))) |>
select(-G_1b, -G_2b, -G_3b, -G_ss) |>
group_by(playerID, lgID) |>
summarise(catcher = sum(G_c),
outfield = sum(G_of),
dh = sum(G_dh),
infield = sum(g_inf),
total_games = sum(G_all)) |>
pivot_longer(catcher:infield,
names_to = "position") |>
filter(value > 0) |>
group_by(playerID, lgID) |>
slice_max(value) |>
select(playerID, lgID, position) |>
inner_join(career)## `summarise()` has grouped output by 'playerID'. You can override using the
## `.groups` argument.
## Joining with `by = join_by(playerID, lgID)`career <- People |>
tbl_df() |>
dplyr::select(playerID, nameFirst, nameLast) |>
unite(name, nameFirst, nameLast, sep = " ") |>
inner_join(career, by = "playerID")## Warning: `tbl_df()` was deprecated in dplyr 1.0.0.
## ℹ Please use `tibble::as_tibble()` instead.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.career <- career |>
mutate(league_dummy = ifelse(lgID == 'NL', 1, 0))
count(career, position)## # A tibble: 4 × 2
## position n
## <chr> <int>
## 1 catcher 415
## 2 dh 83
## 3 infield 1279
## 4 outfield 1165gf_violin(position ~ average, data = career, fill = 'gray85', draw_quantiles = c(0.1, 0.5, 0.9)) |>
gf_labs(x = "Batting Average",
y = "")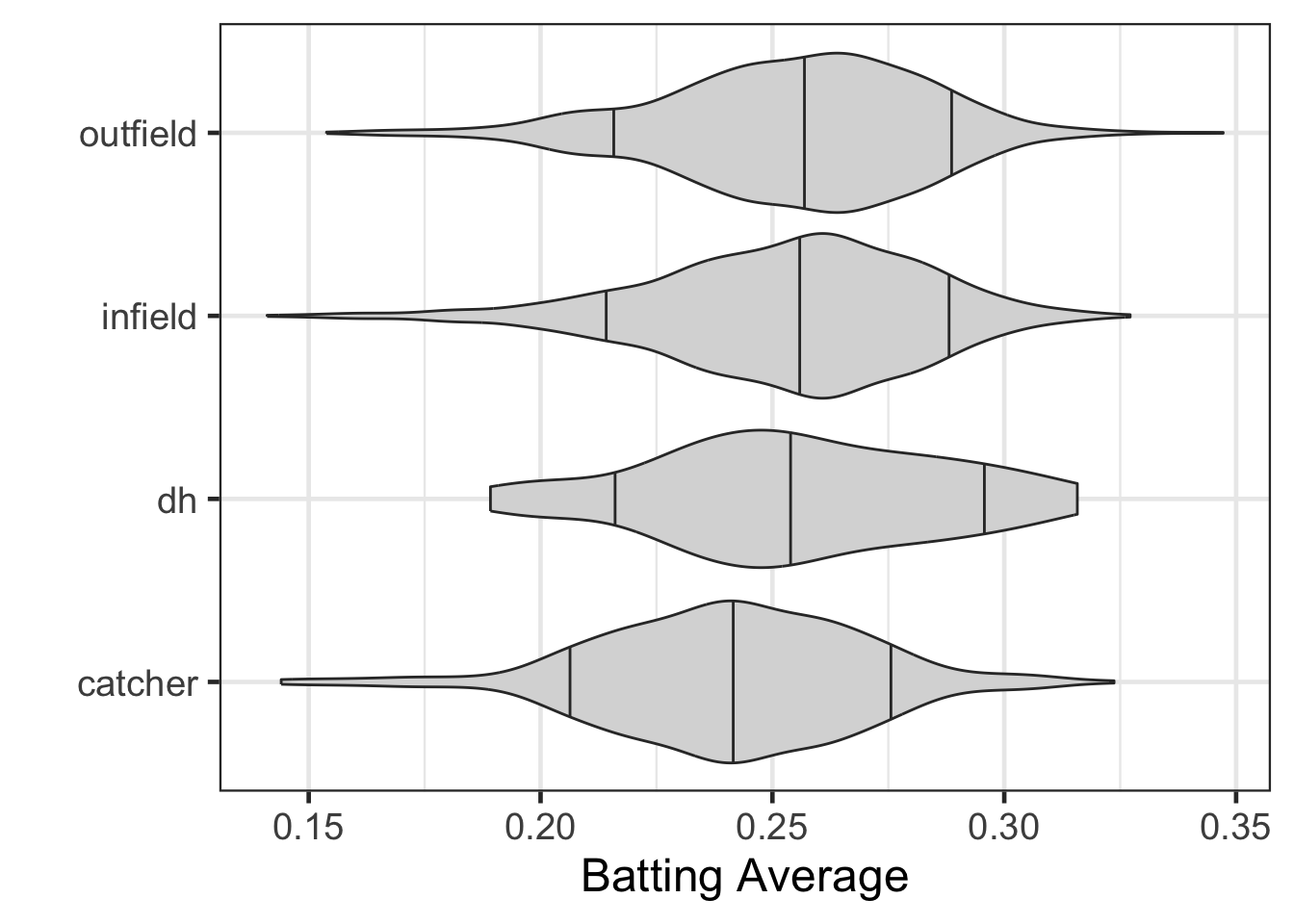
career <- career |>
mutate(outfield = ifelse(position == 'outfield', 1, 0),
infield = ifelse(position == 'infield', 1, 0),
catcher = ifelse(position == 'catcher', 1, 0))
head(career)## # A tibble: 6 × 11
## playerID name lgID position H AB average league_dummy outfield
## <chr> <chr> <fct> <chr> <int> <int> <dbl> <dbl> <dbl>
## 1 abbotje01 Jeff Abbott AL outfield 127 459 0.277 0 1
## 2 abbotku01 Kurt Abbott AL infield 33 123 0.268 0 0
## 3 abbotku01 Kurt Abbott NL infield 455 1780 0.256 1 0
## 4 abercre01 Reggie Abe… NL outfield 54 255 0.212 1 1
## 5 abernbr01 Brent Aber… AL infield 194 767 0.253 0 0
## 6 abnersh01 Shawn Abner AL outfield 81 309 0.262 0 1
## # ℹ 2 more variables: infield <dbl>, catcher <dbl>position_lm <- lm(average ~ 1 + outfield + infield + catcher, data = career)
broom::tidy(position_lm)## # A tibble: 4 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 0.255 0.00314 81.3 0
## 2 outfield -0.000610 0.00325 -0.188 0.851
## 3 infield -0.00218 0.00324 -0.672 0.501
## 4 catcher -0.0144 0.00344 -4.19 0.0000288df_stats(average ~ position, data = career, mean)## response position mean
## 1 average catcher 0.2409461
## 2 average dh 0.2553577
## 3 average infield 0.2531783
## 4 average outfield 0.2547475